Foundation models and beyond

In November of 2024, Maxwell Zeff wrote about AI labs change of direction, as foundation model development started improving more slowly than before:
Everyone now seems to be admitting you can’t just use more compute and more data while pre-training large language models and expect them to turn into some sort of all-knowing digital god.
Following the release of GPT-5, Cal Newport questioned what happens if A.I. doesn’t get much better than it already is (emphasis mine):
In the aftermath of GPT-5’s launch, it has become more difficult to take bombastic predictions about A.I. at face value, and the views of critics like Marcus seem increasingly moderate. Such voices argue that this technology is important, but not poised to drastically transform our lives. They challenge us to consider a different vision for the near-future—one in which A.I. might not get much better than this.
Over the past few years tech workers have been told that A.I. is going to replace us. That artificial general intelligence (A.G.I) was so close that we needed to start thinking about a future when there will be no work. More recently A.I. has been blamed for layoffs and slow hiring.
But if foundation model development is slowing, what are we to expect next? To put all this into context, we need to look a little deeper at what happened and where AI development is today.
Foundation Models
From a technological point of view, foundation models are not new — they are based on deep neural networks and self-supervised learning, both of which have existed for decades. However, the sheer scale and scope of foundation models from the last few years have stretched our imagination of what is possible. - On the Opportunities and Risks of Foundation Models
Most of the recent improvements in A.I. have focused on foundation models. Large Language Models (or LLMs for short) are one very popular kind of foundation model. However it’s important to realize foundation models aren’t limited to language. They can be audio, video, or image based. DALL-E is a foundation model that can create images and Sora is a model (and now a Social app) that can create short form videos.
As the quote in the beginning of this section says, it’s the “sheer scale and scope” of these foundation models that has people running their mouths and imaginations about the future. So let’s take a look a model improvements over the last few years:
More is Better
In January of 2020, researchers from a little know company called OpenAI published a paper titled Scaling Laws of Neural Language Models. The 30 page paper has a lot of technical details but the gist is in the summary:
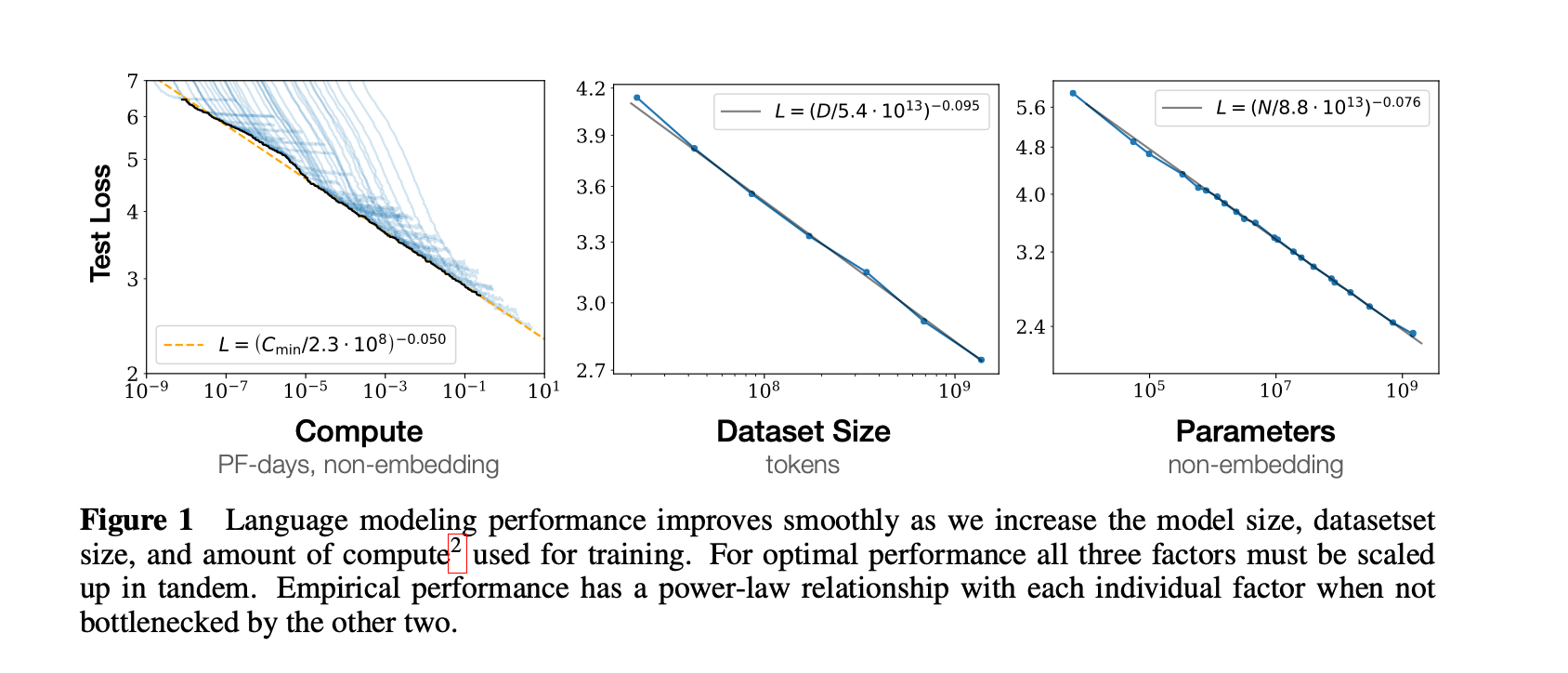
It says language models (LLMs) performance improves as model size, dataset size and compute size increase. While OpenAI called them ‘Scaling Laws’, they were more like observations about performance, rather than unbreakable laws of the universe. With this framework, it gave OpenAI a hypothesis to test. They threw more at the problem:
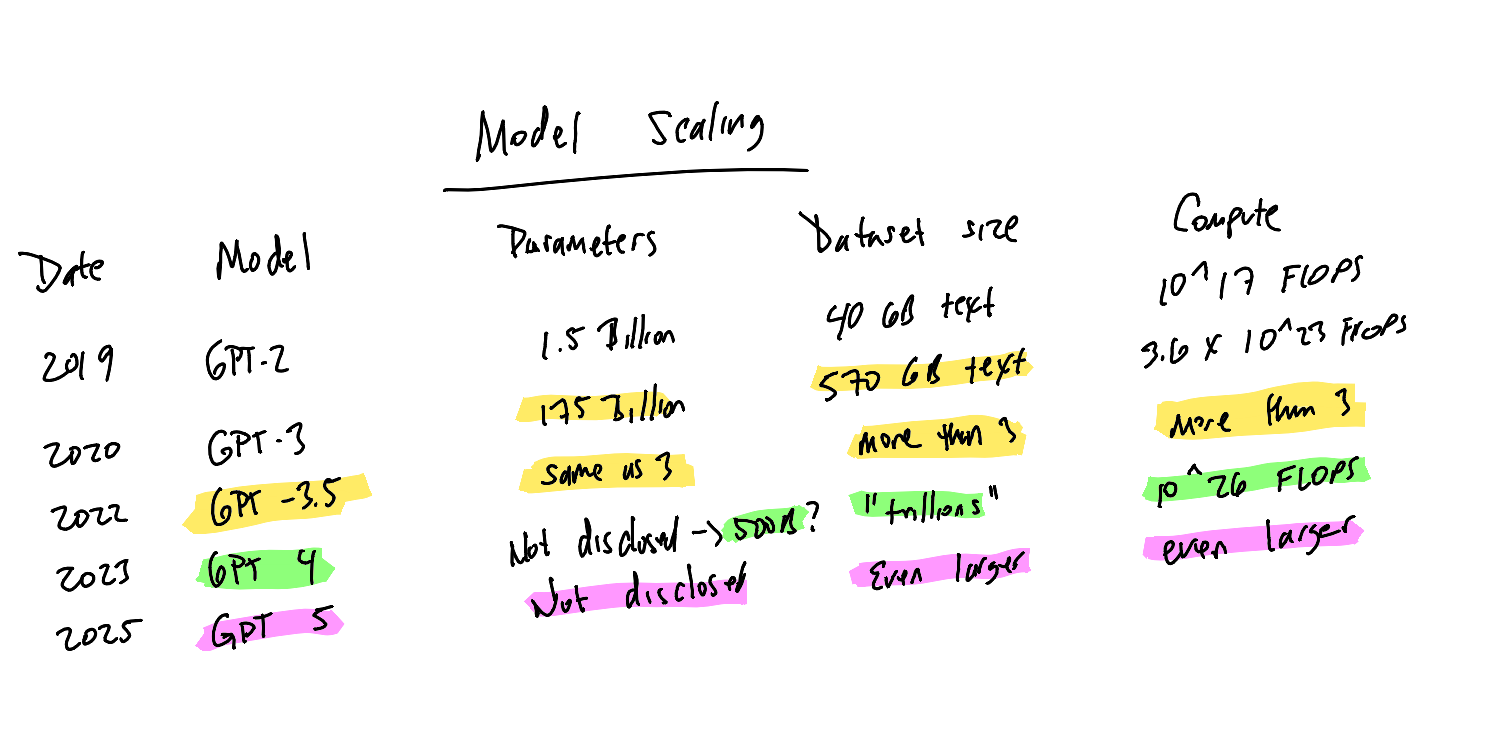
As the chart above shows, OpenAI threw more parameters, data and compute to pre-train the models. The results kept impressing:
- In 2020, the GPT-3 became massively better than its predecessor GPT-2. It responded to questions (prompts) in a much more realistic and complete way. You could have a real conversation with the model.
- In 2022, GPT-3.5 became massively better than GPT-3. Bill Gates publicly said it could finally answer advance placement biology questions. He was also impressed by it’s advice to a father with a sick child.
- By the end of 2022, ChatGPT debuted using GPT-3.5 and the rest of the world got to see how good these models had gotten.
- In 2023, when GPT-4 came out it was another massive leap over GPT-3.5.
Year over year improvements led to wild predictions about what foundation models could do. Lots of hype ensued, some positive and some not so.
The need to ensure it wouldn’t turn against humans became a real concern. If A.I. might be as smart as a high schooler - what impact might that have? How might that “intelligence” do bad things? There was (and still is) lots of talk about how to regulate it.
An arms race followed. All companies had to do was throw more parameters, data and compute at the problem. All of a sudden Grok, Meta, Google and others had caught up by doing the same thing. It worked until scaling didn’t yield massively better results.
The Model Plateau
By November of 2024, pre-training bigger models wasn’t yielding the same returns as in the past. When pure scaling failed, AI labs shifted to post-training optimizations to find ways to make improvements.
The realization of a plateau didn’t set-in more widely until GPT-5 was released earlier this year. It was billed as a massive improvement over GPT-4, but it ended up as a rather modest improvement in some areas. Turns out there are limits on how quickly foundation models can be improved upon.
Although we can hope that’s the end of the hype, it’s not the end of the story. Even if foundation models only make gradual advances over the next few years, there are plenty of other places where advancements are coming.
Here come the Agents

Today’s A.I. chatbots do more than just generate text. They search the web, transcribe what you say, respond in voice, create images, create videos and write code. These products can take your request, break it into multiple smaller tasks and give them out to other models to carry out. When they are done, another model puts tasks together and presents them to you. Almost like a virtual assistant.
Collectively this functionality is referred to as an agentic system. (The term comes from the word agency which means to have the capacity to act independently.) The diagram below shows the various parts of an agentic system:
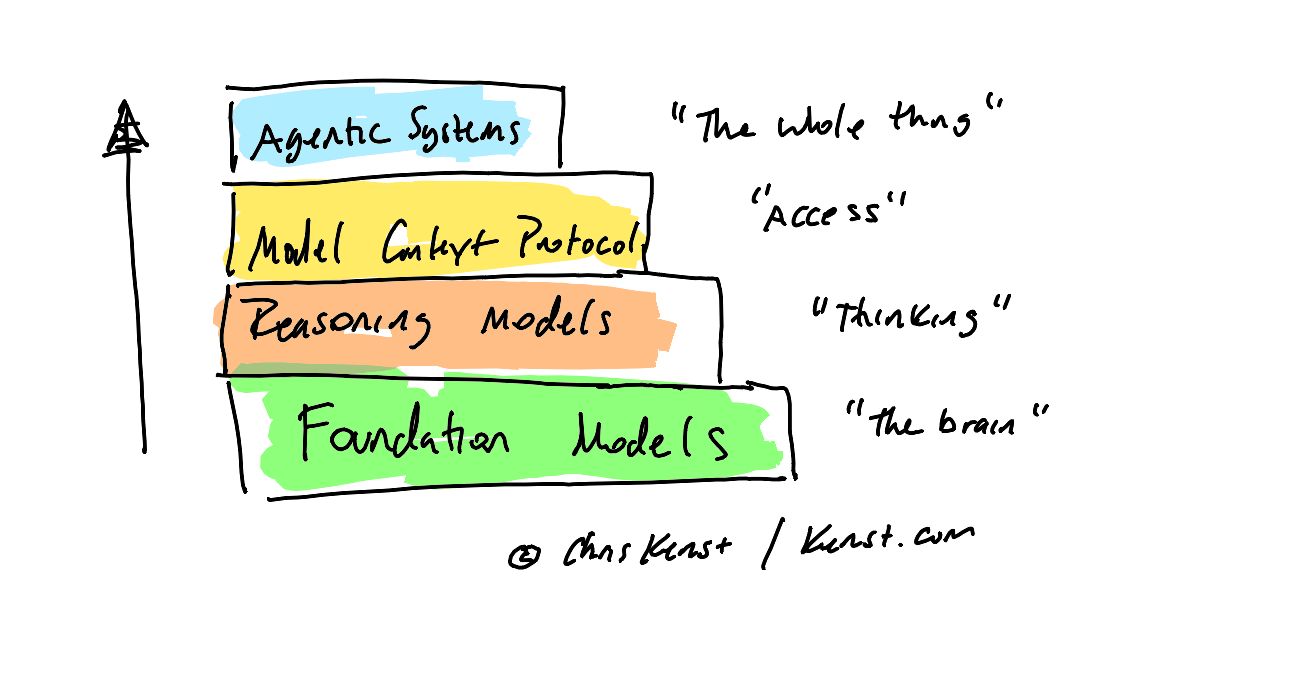
Foundation models are the starting point because they contain the general “intelligence” of the system, but putting a bunch of them together isn’t enough. You need something that will make better sense of the users requests (prompts).
That something is called a reasoning model. Reasoning models are meant to work through problems, step by step, rather than predict the next most likely token. It’s the reasoning model’s job to plan and problem solve a given command.
As a problem is worked through, the system will probably need a way to access additional capabilities (think of a command that requires a web search or an image to be created). Open source protocols like Model-Context-Protocol (or MCP) allow models to connect to tools, models, APIs and other real world systems to carry out their tasks.
This layered agentic approach turns a powerful but passive model into an active, automated assistant capable of tackling real-world workflows:
- Want to hold your meetings in Zoom, automatically transcribe everything into text and save those transcripts to Google Docs? Use an agentic system to connect Zoom, an LLM and Google together.
- Got a bunch of old feature flags still in your system that developers have never removed? Let an agent identify them and suggest how to remove them. (https://block.github.io/goose/blog/2025/08/28/ai-teammate/)
- Have some failing automated tests? Ask an agent to investigate the failures, determine what code is causing the failure and then report back.
I have seen more reports (but far too few examples) of teams using agents to help them with their work.
Agentic Systems have their own downsides. Connecting foundation models to general purpose software systems means increasing your security footprint with each connection. Your organization trusts who gets access to a Google Workspace, but if anyone can connect an agent to it, shady things might happen.
Let go of the hype, dig into the details
We expected A.G.I., but we got specialized agents instead.
This alone should convince you not to take any more of the A.I. hype at face value. Yes advancements will continue to show up and in many places. Our challenge is to understand its benefits, and risks. Then we need to figure out how to steer A.I. systems in a way that helps us create value for customers in a way that we can understand, such that we can manage those risks.
I for one am excited to dig into the details. The intersection of software testing, quality and A.I. is so very fascinating but right now I have more questions than answers.
Member discussion